
The quality of data directly determines the quality of insights you are trying to get. In a world where businesses are increasingly relying on data-driven decision, it is essential for modern organizations to build an effective ETL (Extract, Transform, Load) pipeline to move, process, and prepare data from various sources into a usable format ready for analytics. But the most important thing is that without properly testing the quality of data, these pipelines can quickly become conduits for misinformation, inefficiency, and costly errors.
So, what do organizations need to do for data quality management?
They must test the data quality within ETL processes.
This will ensure that the data flowing through your systems is accurate and reliable. A cleaner pipeline ensures trustworthy analytics.
In this article, we will explore the importance, methodology, and best practices to test the quality of data in ETL systems and how to build a cleaner data pipeline.
Evolution of Data Quality in ETL Pipelines
The traditional data quality management processes often worked in silos or in batch processes, which do not properly provide clear visibility to the quality of data. This required data science professionals to rely heavily on manual checks or correcting data after loading. Thus, issues were realized only after they had impacted reports or business intelligence dashboards.
With the growing importance of data-driven decision-making, the rise of cloud data warehouses, real-time data streaming, and data observability platforms, the quality of data has transformed into an automated discipline.
In modern ETL architectures where data is loaded before transformation, data professionals can do profiling and testing earlier, and AI tools can detect anomalies automatically.
So, reactive data cleaning is now slowly moving towards proactive data assurance, and data quality testing is integrated right into the data lifecycle. The global data observability market is expected to reach USD 1.7 billion by 2025 and is projected to soar to USD 9.7 billion by 2034, reflecting a strong compound annual growth rate (CAGR) of 21.3%. (Source: DMR Research)
Importance of Data Quality Testing in ETL
As said earlier, the quality of insights and accuracy of decisions is directly proportional to the quality of data. Gartner once mentioned that poor data quality can lead to loss of annual revenue and missed opportunities. If the data flowing downstream is not complete/accurate, then it can lead to bad analytics, mislead decision-makers, and ultimately impact stakeholder trust.
Let's understand it from an operational point of view. If there is poor-quality data, then it will obviously increase rework and slow down reporting, ultimately adding unnecessary maintenance overhead. This is why several regulatory frameworks like GDPR, HIPAA, or SOX require traceable and accurate data handling.
By testing data quality during ETL, you can ensure only validated, consistent, and complete data is available for analysis, thus helping to get insights faster.
Data Quality Issues in ETL Pipelines
There can be different types of data quality issues in ETL pipelines that can affect insights and quality decision-making.
For example:
If professionals identify these issues early with ETL data quality testing, then they can significantly reduce data corruption and troubleshooting at later stages.
Four Stages of ETL To Apply Data Quality Testing
Data quality management process should cover the entire stages of the ETL pipeline, including:
Extraction – This means validating data at the source. It involves performing schema checks, field completeness tests, or anomaly detection before extraction.
Transformation – In this stage, verify that business logic, joins, and aggregations are correctly applied. The transformation of data should be meaningful and preserve the originality of data without distorting its true nature
Loading – Check if all the data has been received at the database/data warehouse, and see if the data at the source and destination are the same or not.
Post-Load Monitoring – Professionals must also continuously monitor the data post-loading for their consistency, freshness, and relevancy. You can set up an automated alert for anomalies.
By effectively implementing data validation throughout these stages, data teams build a quality data pipeline free from data degradation.
Framework for Effective Data Quality Testing
Now, the important part, what all things need to be taken care of that assure data quality is at par within the ETL pipeline? Well, the following are the essential components of data quality testing:
Data science professionals should use checkpoint-based validation for streaming data or event-based data. There should be a quarantine zone to isolate bad records without disrupting the flow
Following this well-structured framework can help organizations get access to cleaner data.
Making a Cleaner ETL Pipeline: Best Practices
Strategic design and discipline are required to maintain a clean ETL pipeline and get trusted and quality data.

Below are the industry best practices
In the era of AI and machine learning algorithms, you can directly integrate quality checks into ETL workflows using orchestration platforms or CI/CD pipelines
You can store test definitions in code repositories. This ensures a consistent and traceable data
Dedicated quarantine zones will help isolate invalid records for reviewing later, instead of halting the entire pipeline
This will help you improve transparency and help identify the root cause in case there are any quality issues
It is also important to have a clearly defined quality SLA and ownership between producers and consumers
Most importantly, continuously review the quality of data, update quality benchmarks, and refine test logic.
What Tools to Use for Data Quality Testing?
A lot of open-source and commercial data science tools can be used to automate validation and monitoring in modern data quality testing processes.
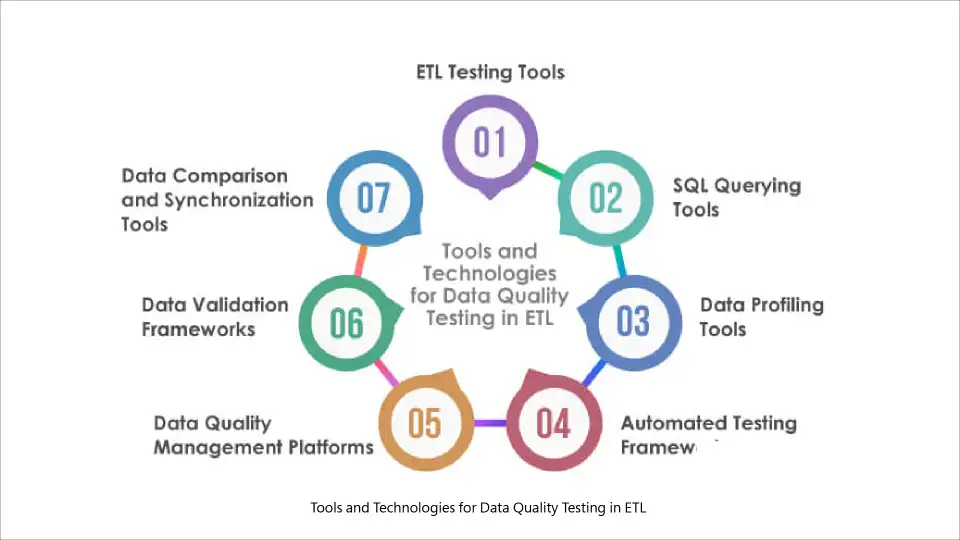
Tools and Technologies for Data Quality Testing in ETL
Some of them are listed below:
Open-source frameworks:
Commercial data observability tools:
ETL/ELT Integrations:
These tools and technologies can significantly enhance reliability and automate monitoring to reduce manual intervention and ensure cleaner pipelines.
Challenges and Considerations
Even after advancements in technology, organizations still have to face several challenges to maintain a high-quality data pipeline, such as:
Example Case Study: From Raw to Reliable Data
Let us understand data quality management with this case study. Consider a retail analytics company pulling sales transactions from different e-commerce platforms. Initially, analysts noticed inconsistencies in daily revenue figures because of duplicate order IDs and a delay in updates from one data source.
So, they integrated Great Expectations into their Airflow ETL pipeline. This helped their team automate the validation process of duplicate data, schema consistency, and completeness checks.
Invalid records were automatically quarantined so that data engineers or analysts could review them manually later. Within three months, their data errors dropped by 80% and dashboard refresh times improved by 40%.
Through this transformation, we can conclude how proactive data quality testing can improve accuracy and performance in real-world ETL environments.
Final Thoughts!
Data quality testing is a very important element in the modern data ecosystem. Organizations must embed quality validation across every stage in their ETL process. This will help them maintain data integrity, build trust, and reduce the cost of poor-quality data.
The earlier the organizations adopt a proactive and automated testing framework; the sooner they will gain a strategic advantage and will be able to deliver quality insights faster. With data pipelines continuing to evolve with AI and real-time processing, the future of ETL will mostly be influenced by intelligent systems that not just move data efficiently but also guarantee quality data at every step.
USDSI® offers the most comprehensive data science certifications for various levels of data science careers. Whether you are looking to design and implement an effective data/ETL pipeline or want to transform your existing data infrastructure, their data science programs can be truly transformative for your career.
This website uses cookies to enhance website functionalities and improve your online experience. By clicking Accept or continue browsing this website, you agree to our use of cookies as outlined in our privacy policy.