
The way organizations store their data can influence their application’s speed, efficiency, and scalability. The two most widely used database architectures are Row databases and columnar databases. Both these have different approaches to storing and retrieving data.
On one hand, row databases assist with faster transactional operations, whereas on the other hand, columnar data warehouses are best suited for analytical queries and large-scale data processing.
Therefore, for developers and organizations who want to build high-performance systems, it is important to understand how these two function. Factors like the nature of workloads, their type, whether it is transactional (OLTP) or analytical (OLAP), etc., also influence the choice between these two database architectures. Let us understand their strengths and limitations that will guide you with proper implementation.
What is a Row Database?
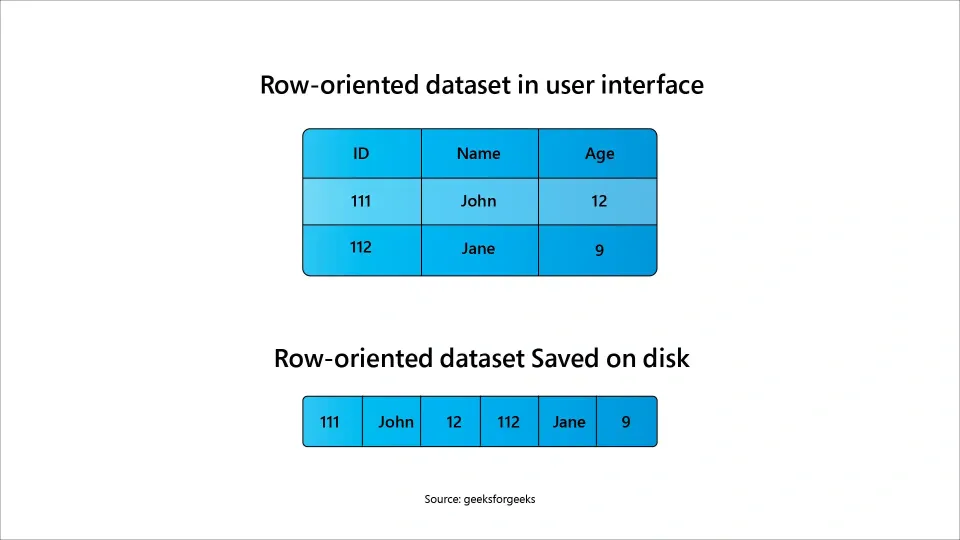
A row database stores data record by record, i.e., all the fields of a single row are stored together.
Example – an entry of customer records with name, email, address, etc., is stored as a single unit.
This type of storage model is suitable for transactional systems in which frequent inserting, updating, or retrieving of complete records is required. Row database is useful in applications like:
Advantages of Row Databases
Row databases are widely preferred by organizations for a wide range of operations systems as they offer several advantages as follows:
This is why organizations highly prefer it for applications where high concurrency and reliability are important.
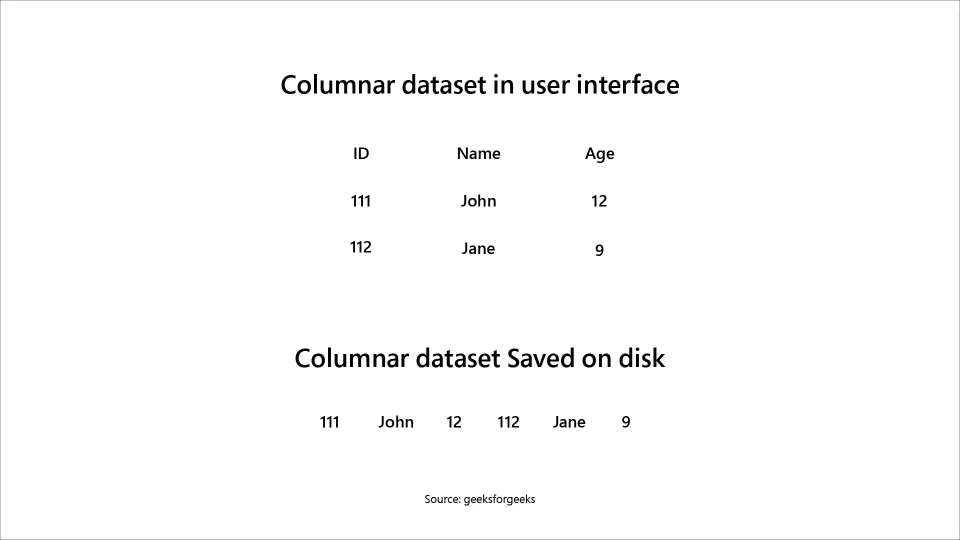
What is a Columnar Database?
The Columnar warehouse is used to store data in columns rather than rows. Here, all the values of a specific column, such as the customer's name and transaction amounts, are stored together.
This type of database architecture is better suited for analytical workloads, as in this case, queries need only a subset of columns. Columnar databases only read the necessary columns, which reduces disk I/O and thus helps improve query performance significantly.
Columnar databases are used in:
Advantages of Columnar Databases
Columnar databases power modern analytics and enhance big data workloads. They offer the following advantages:
These advantages make them suitable for data lakes, data pipelines, data integration platforms, machine learning pipelines, etc.
Columnar Database vs. Row Database: Key Differences Explained
This section explores the key differences between a columnar database and a row database. This will help you make better decisions in choosing the right one for your business needs.
Row database: It stores complete records together in rows
Columnar database: It stores data column-wise and groups similar attributes
This difference influences how efficiently they can process queries
Row database: It performs best when retrieving entire records.
Example: access to all fields in a row is required while fetching a user record
Columnar database: It performs best in analytical queries where aggregations are involved.
Example: SUM, AVG
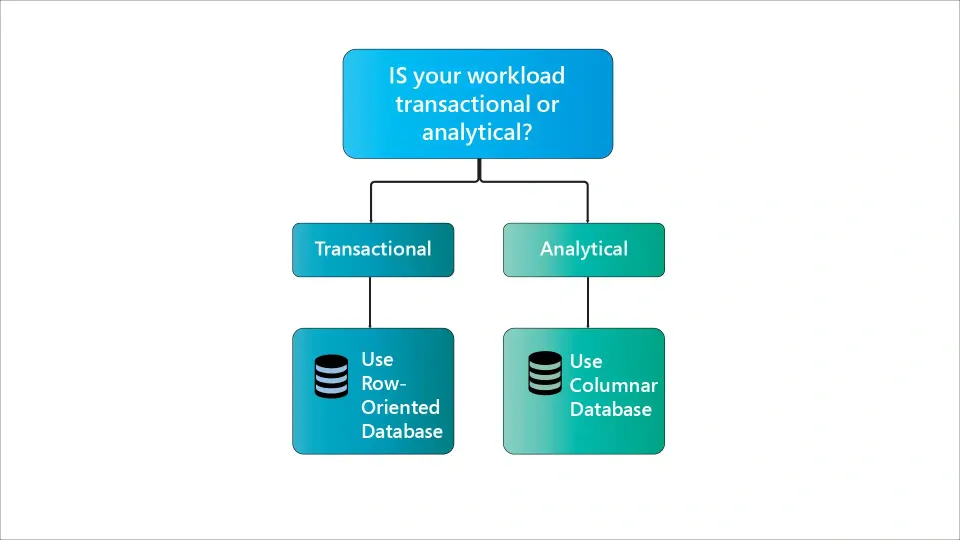
Row database: It is optimized for Online Transaction Processing (OLTP), as they require fast writes and updates
Columnar database: It is optimized for Online Analytical Processing (OLAP) as a columnar database helps with fast reads and aggregations.
Row database: As the whole record is stored together, the row database supports frequent inserts, updates, and deletes efficiently.
Columnar database: It processes writes in batches and therefore is not so efficient for frequent row-level updates
Row database: Has lower compression efficiency as they have mixed data types within each row
Columnar database: Has higher compression efficiency as similar data types are stored together and supports better encoding techniques
Real-world Use Cases
Both columnar database and row database have unique approaches and therefore are suitable for different applications. The table below focuses on different use cases to help you make the right choice:

Explore Hybrid Approach
Modern data architectures rely on a hybrid approach in which they leverage the strengths of both row database and columnar data warehouses. In the hybrid model, the row database handles transactional data first, where fast inserts, updates, and real-time operations are needed.
After that, the data is pushed down the data science pipeline into columnar databases. Here they are processed for analytics, reporting, and business intelligence.
This separation of operational and analytical workloads helps organizations to perform better, scale operations, and achieve greater cost efficiency. Many organizations adopt this ‘best of both worlds’ strategy, where they enjoy seamless real-time operations as well as generate powerful insights efficiently.
The Way Forward!
By now, you must have understood the difference between row database and columnar database, their strengths, limitations, and use cases. However, the real debate is not which one is better, but which one is suitable for your use case.
Row databases are best for transactional data in which fast writes and real-time updates are needed. On the other hand, columnar databases are useful for analytics and provide greater performance for large-scale queries and aggregations.
The best way to determine the best approach is to understand your workload, whether it is analytical or transactional. If you want both, go for a hybrid database architecture where you can enjoy efficient and scalable solutions and build modern data-driven organizations.
This website uses cookies to enhance website functionalities and improve your online experience. By clicking Accept or continue browsing this website, you agree to our use of cookies as outlined in our privacy policy.