
The way organizations use data has evolved over the years, especially after the inception of technologies such as artificial intelligence and machine learning, across diverse business operations.
For a long time, modern data stacks were built around data pipelines, data warehouses, and business intelligence applications that powered data analytics within organizations.
But the rise of generative AI, large language models (LLMs), and AI agents is now redefining this AI and data infrastructure.
For instance, traditional data stacks were built keeping analytics and reporting in mind for structured data. But today, AI systems can work on a variety of datasets, including unstructured data like documents, emails, social media feeds, images, etc.
Gartner reveals data center systems spending is expected to grow 31.7% in 2026, surpassing $650 billion mark. This growth shows the rapid expansion of infrastructure needed to support AI workloads and advanced data platforms.
Here is a detailed insight into how AI is redefining the modern data stack and what organizations need to be prepared for.
Traditional Data Stack: Built for Analytics
The traditional data stack follows a well-defined workflow including the following steps:
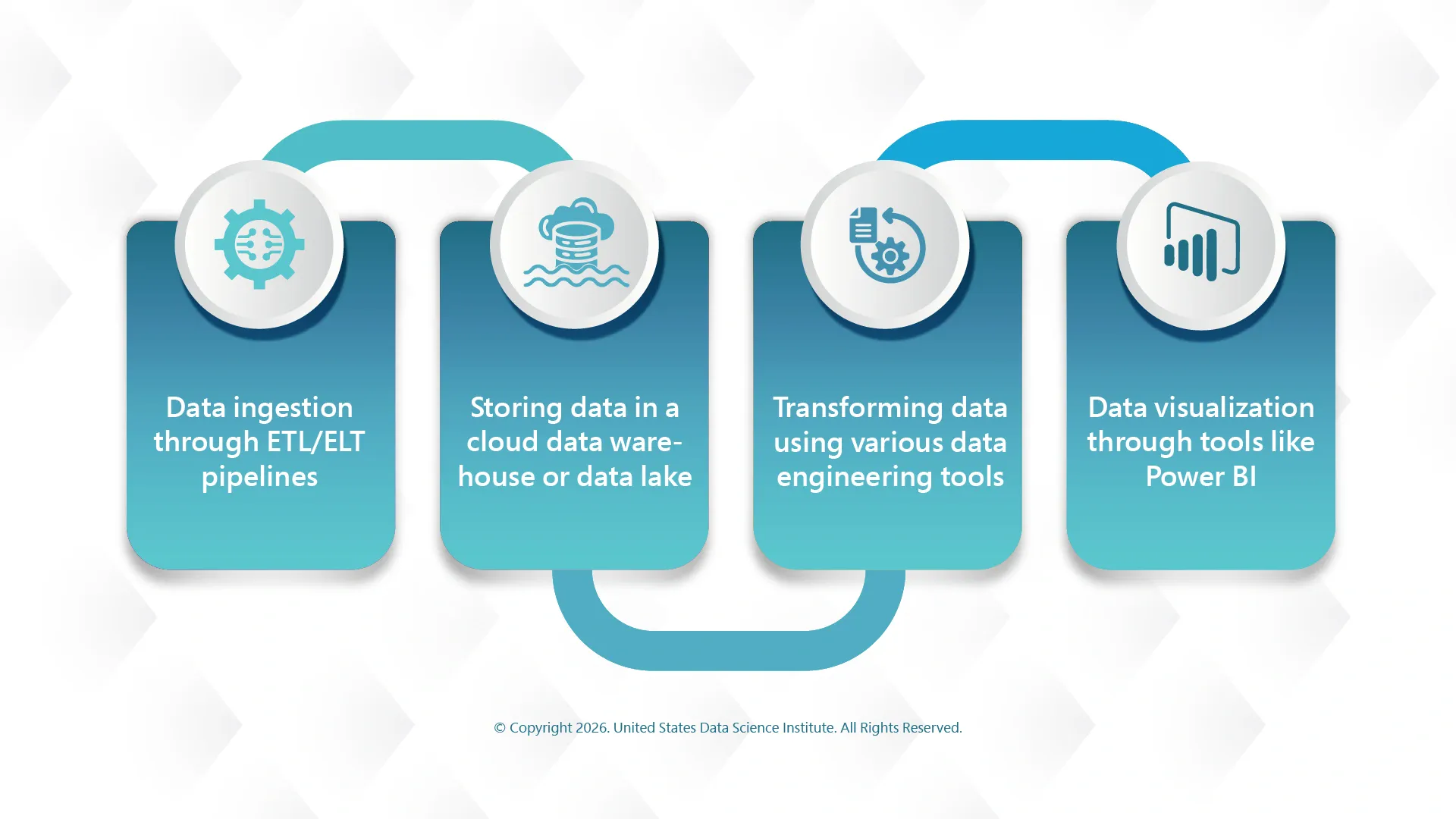
Though this is an efficient way to generate reports and support data-driven decisions, it is typically built for human consumption of data.
All the traditional analytics systems rely on structured tables and SQL queries. These are great for dashboards and reporting, but struggle to handle unstructured or semi-structured data that modern AI systems rely on.
How Does AI Disrupt the Modern Data Stack?
AI systems are quite different from traditional analytics and data science tools in the way they consume and process data. Large language models and AI agents require contextual information and access to diverse datasets in real time.
According to Gartner, 40% of enterprise applications will embed AI agents by 2026, but most current technology architectures lack the infrastructure needed to support them effectively.
Here are some important factors that determine the modern AI and data infrastructure:
AI applications rely more on documents, customer interactions, transcripts, multimedia content, etc. This valuable information was previously ignored by traditional analytics and data pipelines.
For effective operation, AI applications require access to data in real-time. For them, instant data retrieval and processing are more important than batch analytics.
The biggest advantage of AI systems is that they can analyze and act on data without human intervention, and hence their data architecture should be designed accordingly.
Because of these requirements, organizations need to redesign their AI and data infrastructure that can efficiently support AI workloads.
Did you know that most AI projects fail, mostly because of poor data and data infrastructure? In this insightful read, Rethinking AI Adoption: Strategic Lessons from Five Enterprise-Level Failures, learn how data science leaders can formulate a strategy for greater AI success.
AI-Native Data Architectures
Now that traditional data stacks are inefficient, organizations need to move towards AI-native data stacks to support modern AI systems. This means integrating traditional data pipelines with modern AI infrastructure that assists organizations in operationalizing AI at scale.
In this type of stack, data is not prepared only for dashboards, but it is treated as the foundation for intelligent systems that can reason, generate insights, and automate actions by themselves.
Some of the important components of AI-native data architecture include:
This helps AI systems to retrieve relevant information, analyze it, and generate actionable and insightful outputs.
Also read: How Will Data Lakehouses Transform Your Analytics and ML Workflows?
This article discusses how data science leaders can break down data silos with modern data architecture and boost data analytics and data management for modern ML workflows.
AI Agents Transforming Data Workflows
The biggest leap in the field of enterprise AI so far is probably the emergence of AI agents – autonomous systems that can reason, plan, and act on even multi-step tasks by themselves.
They can understand the problem, retrieve relevant information for the problem from multiple sources, and take the required action. This is transforming data workflows in several ways:
AI agents can autonomously explore datasets, identify anomalies, and generate insights
They can detect if there are any issues in data pipelines, diagnose their causes, and automatically implement fixes
It also eliminates the need for users to navigate complex dashboards. They can simply ask AI systems questions and get output in natural language
Importance of Context and Semantic Layer
Context has never been so important as it is today, especially when the AI systems have started interacting with enterprise data directly by themselves. This mandates AI models to understand the meaning and context of data properly to execute the required task. Organizations must address this challenge by building semantic or context layers within their data architecture.
This layer is used to store contextual information such as:
Semantic layers provide these structured contexts and ensure AI systems interpret data correctly. In short, they can be termed as the knowledge backbone of AI-powered organizations.
Preparing for the Future of Data and AI
The rapid advancement and adoption of generative AI and autonomous agents are redefining how organizations design their enterprise data strategies. They need to treat AI as an integral part of data infrastructure instead of treating it as a separate layer. They must design systems where data and AI can work together.
Here's what organizations can do:
To sum up!
The rise of AI has forced organizations to redefine their AI and data infrastructure. The traditional data stacks are inefficient for modern AI-native systems as they cannot handle unstructured data and do not effectively support real-time processing.
With AI agents, semantic layers, and interoperable architecture becoming more common, organizations must take action to modernize their data strategies. Those who can successfully evolve their data stack will also be able to leverage the full potential of AI and use all kinds of structured and unstructured data to gain insights to boost their innovation and efficiency.
This website uses cookies to enhance website functionalities and improve your online experience. By clicking Accept or continue browsing this website, you agree to our use of cookies as outlined in our privacy policy.