
Machine learning has become an applied science, and it has been incorporated into production systems in all major industries. Scikit-learn remains at the centre of Python's ML ecosystem, driving workflows that take data from raw input to deployable models.
Adoption is a process that is picking up speed. The global machine learning market size is expected to reach USD 126.91 billion in 2026, expanding at a CAGR of 33.66% (Precedence Research). With the growing adoption of AI and machine learning in business, Scikit-learn continues to be one of the most popular Python libraries for developing scalable, interpretable, and production-ready ML models.
In this blog, we will discover what modern Scikit-learn is like in 2026 and its importance for Python ML pipelines, machine learning algorithms, and its integration with NumPy, SciPy, and Pandas.
What is Modern Scikit-Learn
Scikit-learn is an open-source Python library developed using NumPy, SciPy, and Matplotlib. It offers a consistent API for supervised learning, unsupervised learning, preprocessing, model selection, and evaluation.
Scikit-learn has undergone a great transformation. Recent releases added metadata routing, better estimator validation, and native pandas DataFrame output through the set_output() API. The updates allow for a much clearer and easier way to build clean, production-grade ML pipelines without workarounds.
Why Scikit-Learn Still Matters in Python ML Workflows
While deep learning frameworks are getting more popular, scikit-learn news in 2026 remains relevant for one simple reason: Most enterprise ML runs on structured data, not images or sequences of text.
When you want to use the scikit-learn library, choose it if:
Key Benefits of Modern Scikit-Learn
One of the main principles of scikit-learn design is consistency and composability. All estimators, from simple to complex, have the same interface: fit(), .predict(), and transform().
Key capabilities include:
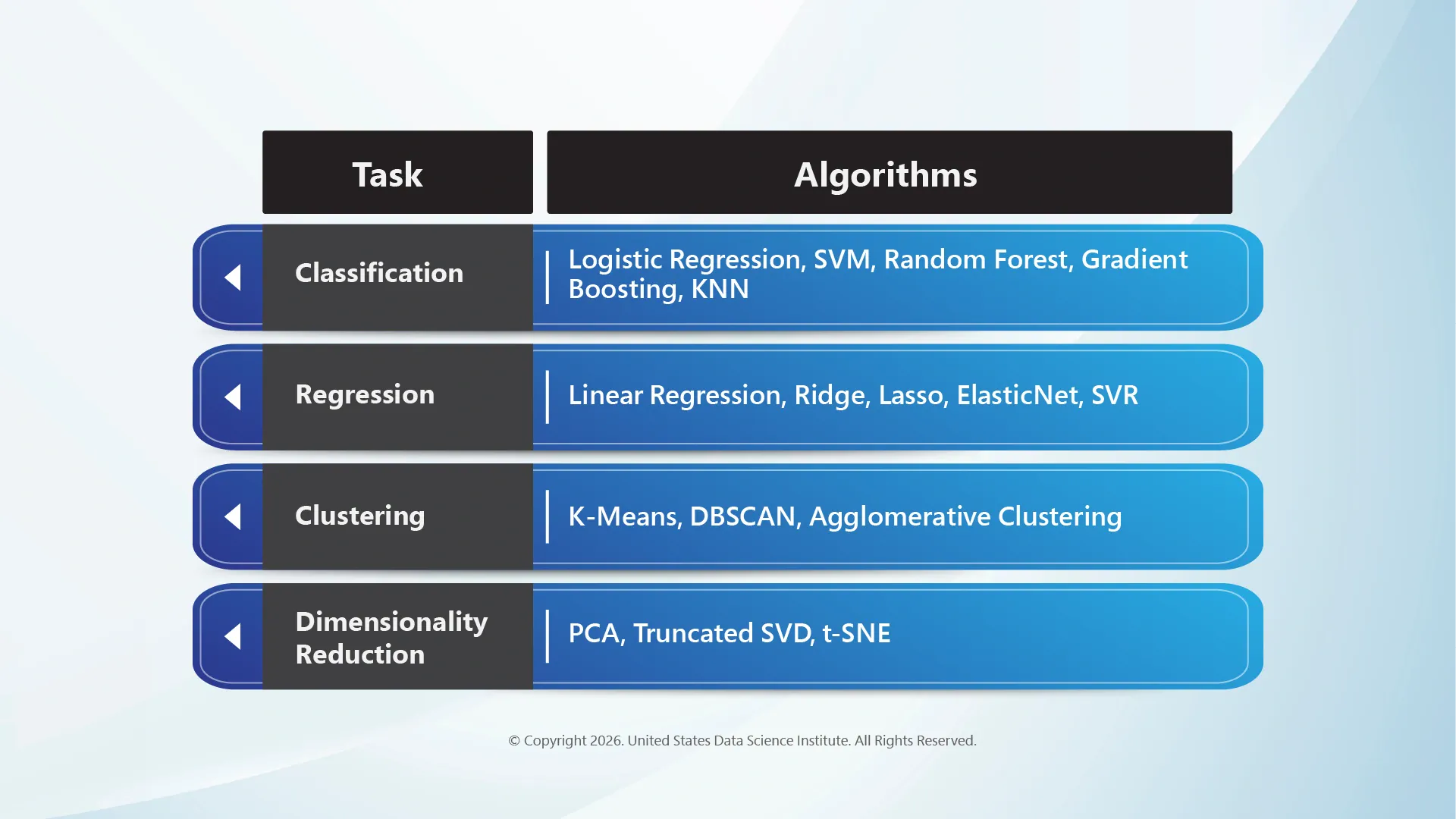
Scikit-Learn Supporting ML Algorithms
Scikit-learn covers the full spectrum of classical machine learning algorithms:
How Does Scikit-Learn Integrate With NumPy, SciPy, and Pandas?
Scikit-learn fits into the scientific Python world via NumPy, SciPy, and Pandas. The core data structures of NumPy are used, and SciPy can be used to implement sparse matrix operations, such as support for algorithms like SVM and TruncatedSVD. The DataFrames' column names are preserved during transformations with set_output as (transform="pandas").
According to USDSI®, Data Visualization in Python: Top Libraries, Tools & Techniques, visualization libraries like Matplotlib, Seaborn, Plotly, and Bokeh transform the output of models into easily understood and decision-making insights for stakeholders.
Step-by-Step Model Building Workflow in Scikit-Learn
Install via pip in any Python environment. Confirm the installation by importing the library and checking the version output.
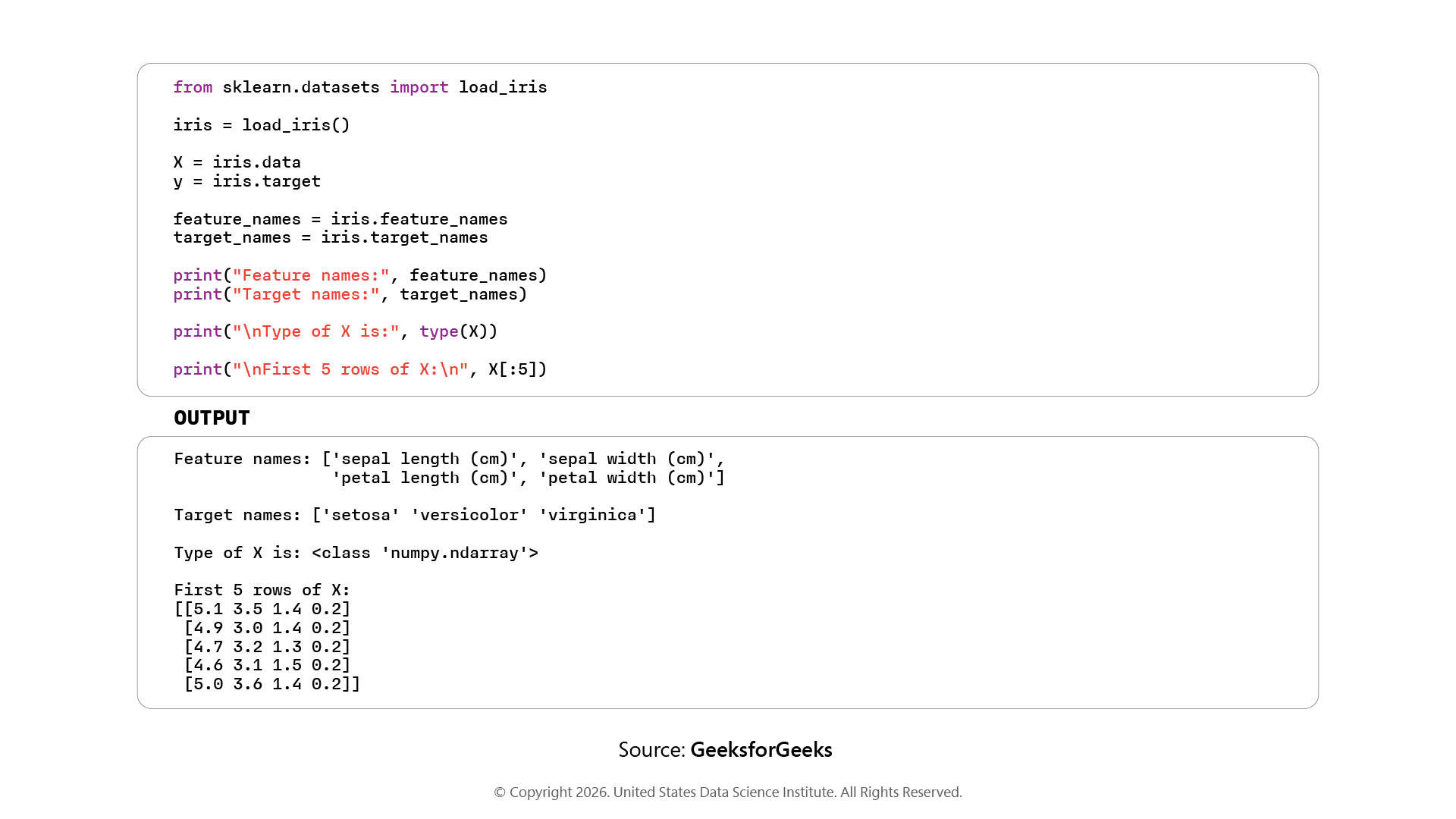
Step 1: Loading a Dataset and Defining Features and Target Variables
Built-in datasets: sklearn.datasets, External files: Pandas read_csv(). If loaded, divide the data into a feature matrix, X (all of the input columns), and y (the label or value to predict; this is the target variable).
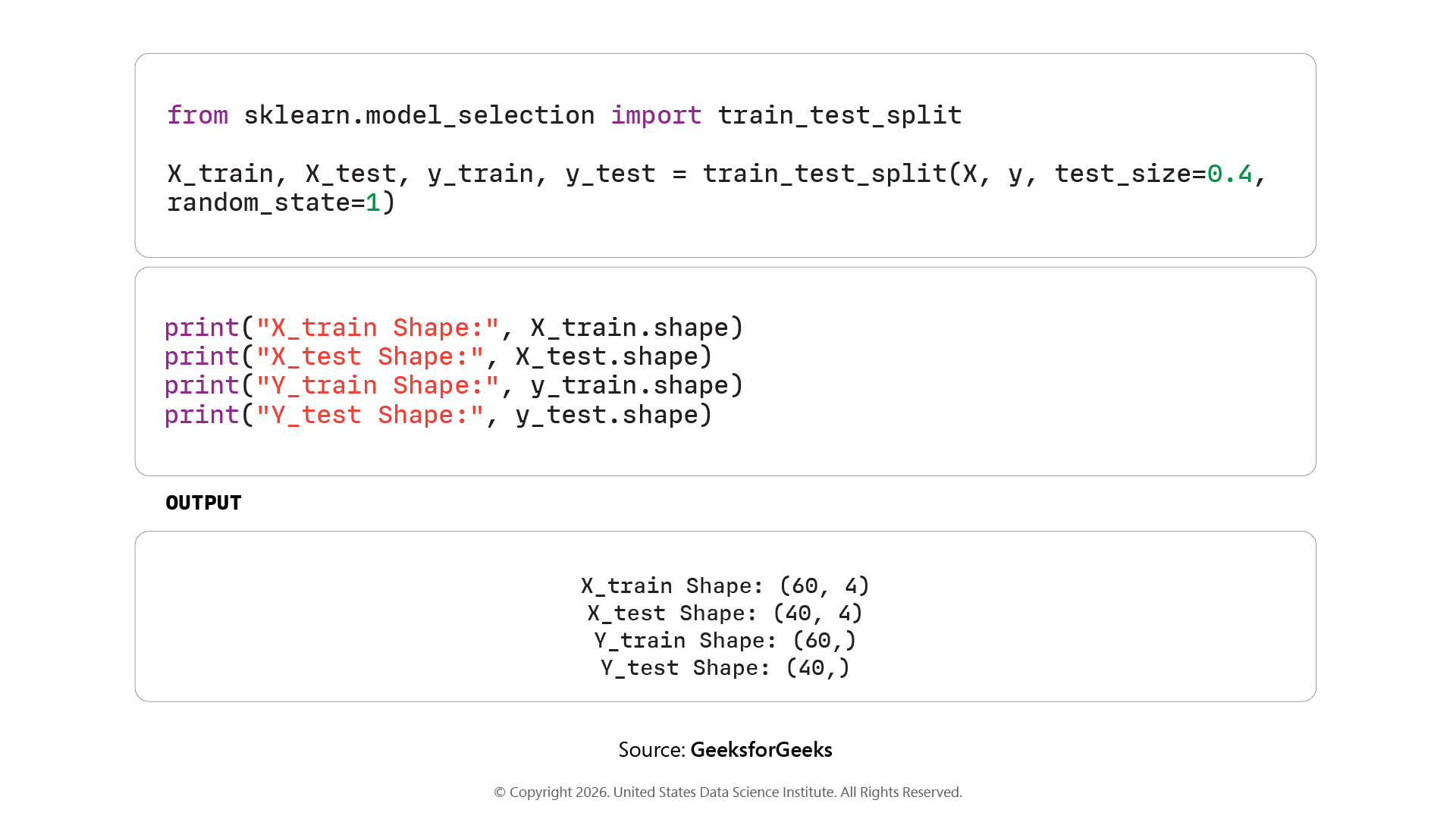
Step 2: Splitting Data Into Training and Testing Sets
Use train_test_split() to divide data into training and testing sets. Set test_size=0.4 for a 60/40 split and random_state=1 for reproducibility.
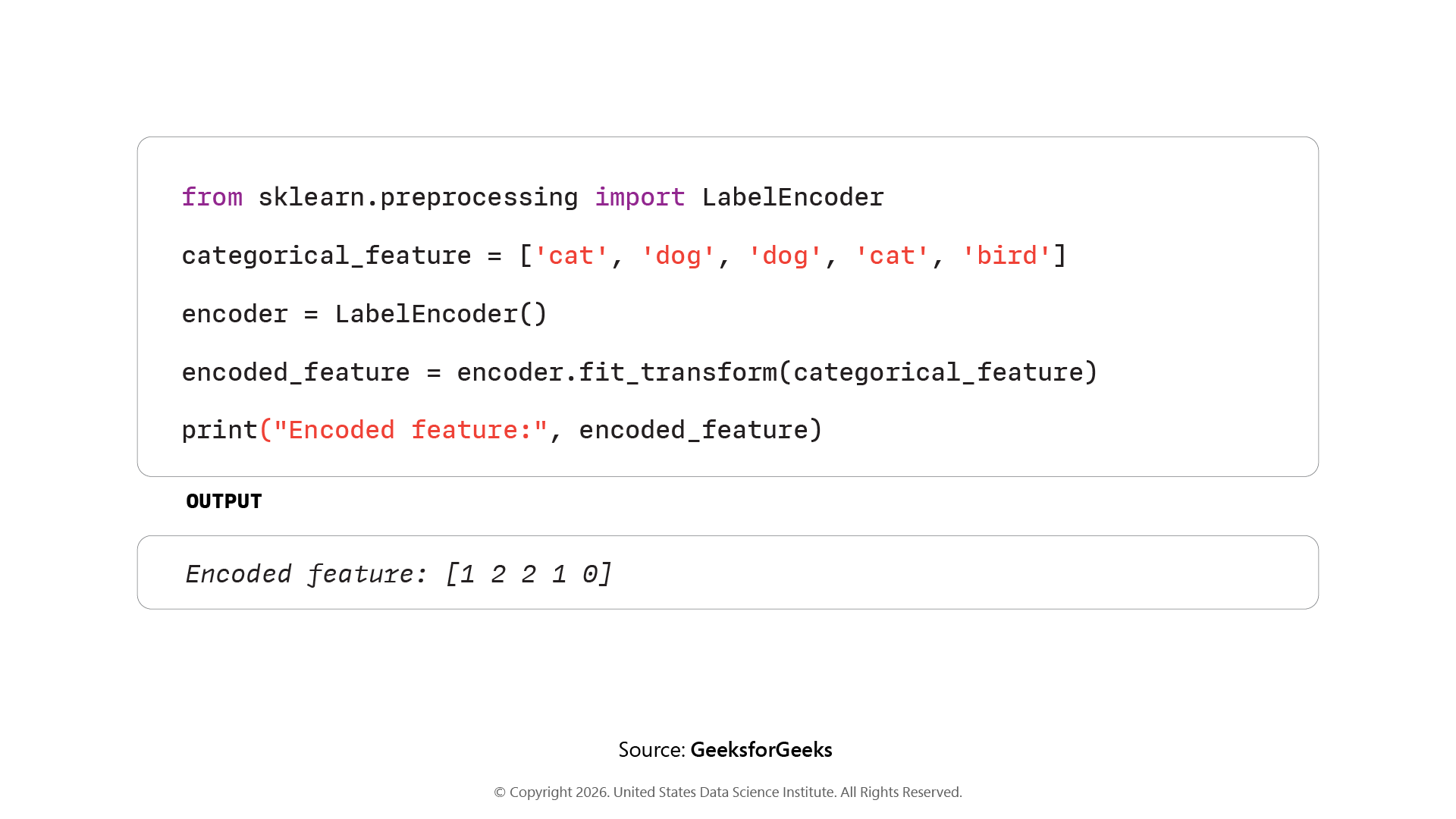
Step 3: Handling Categorical Data, Label Encoding, and Encoding
Label Coding: Label Encoding converts categories into integers using fit_transform(), suitable for ordinal data.
One Hot Coding: One-Hot Encoding creates binary columns per category, which is correct for nominal features with no natural order.
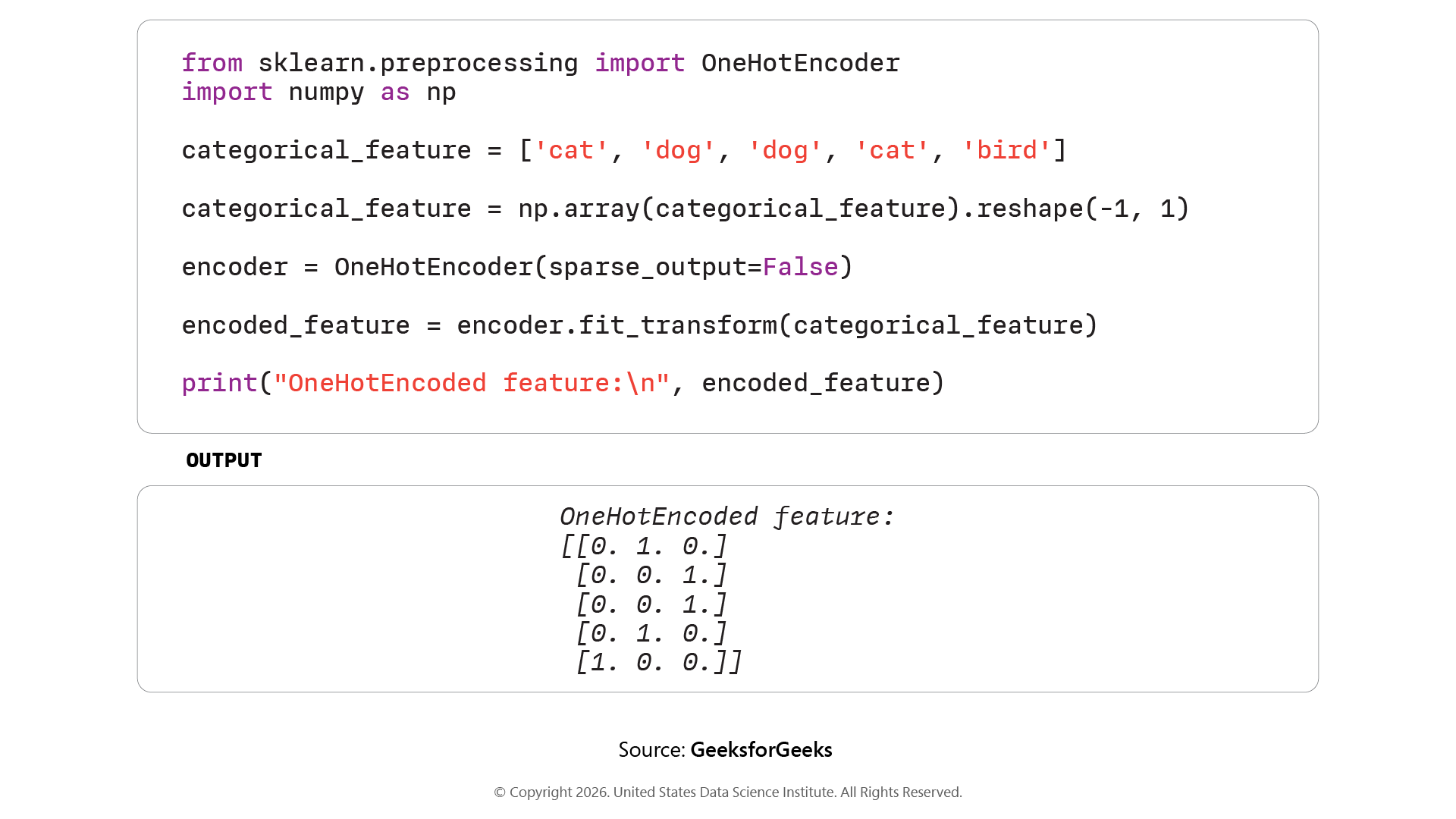
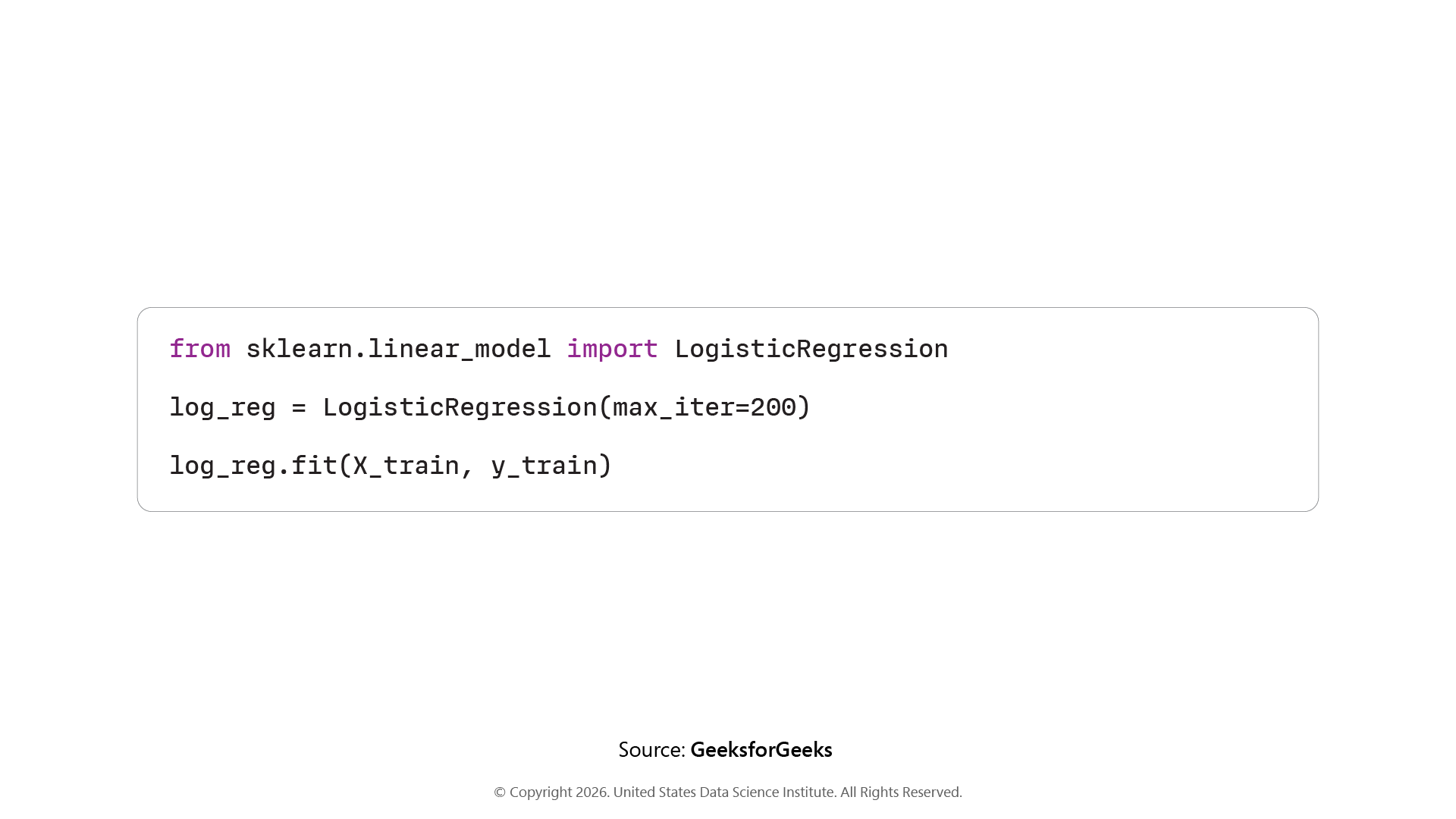
Step 4: Training the Model
Create a Logistic Regression model and train it using our training data. The max_iter=200 just gives the model enough iterations to properly converge. Once .fit() runs, the model has learned from the data and is ready to make predictions.
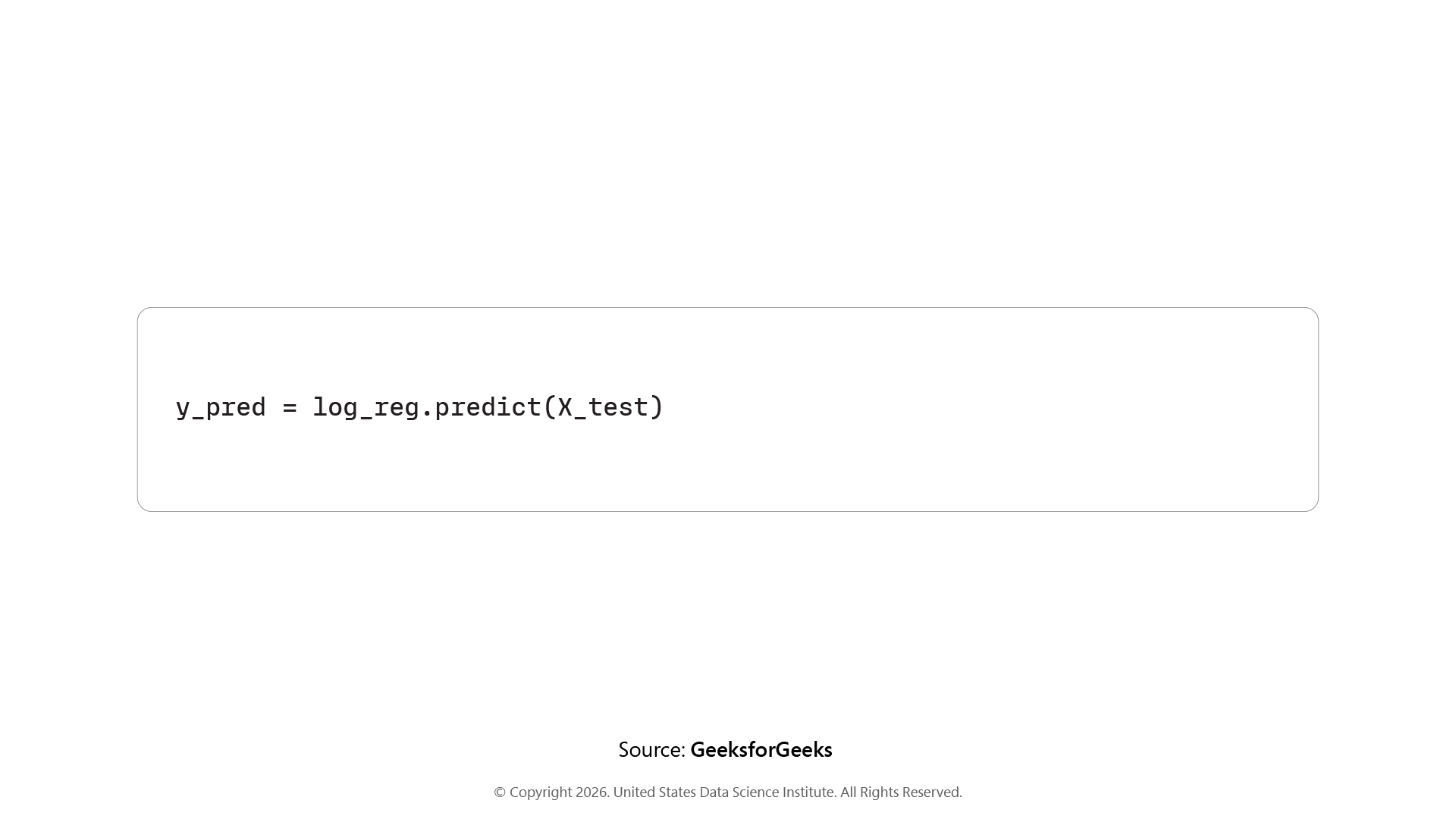
Step 5: Making Predictions
After training, run the model on test data using .predict(X_test) and store the results in y_pred. These are the model's guesses that we'll compare against actual values later.
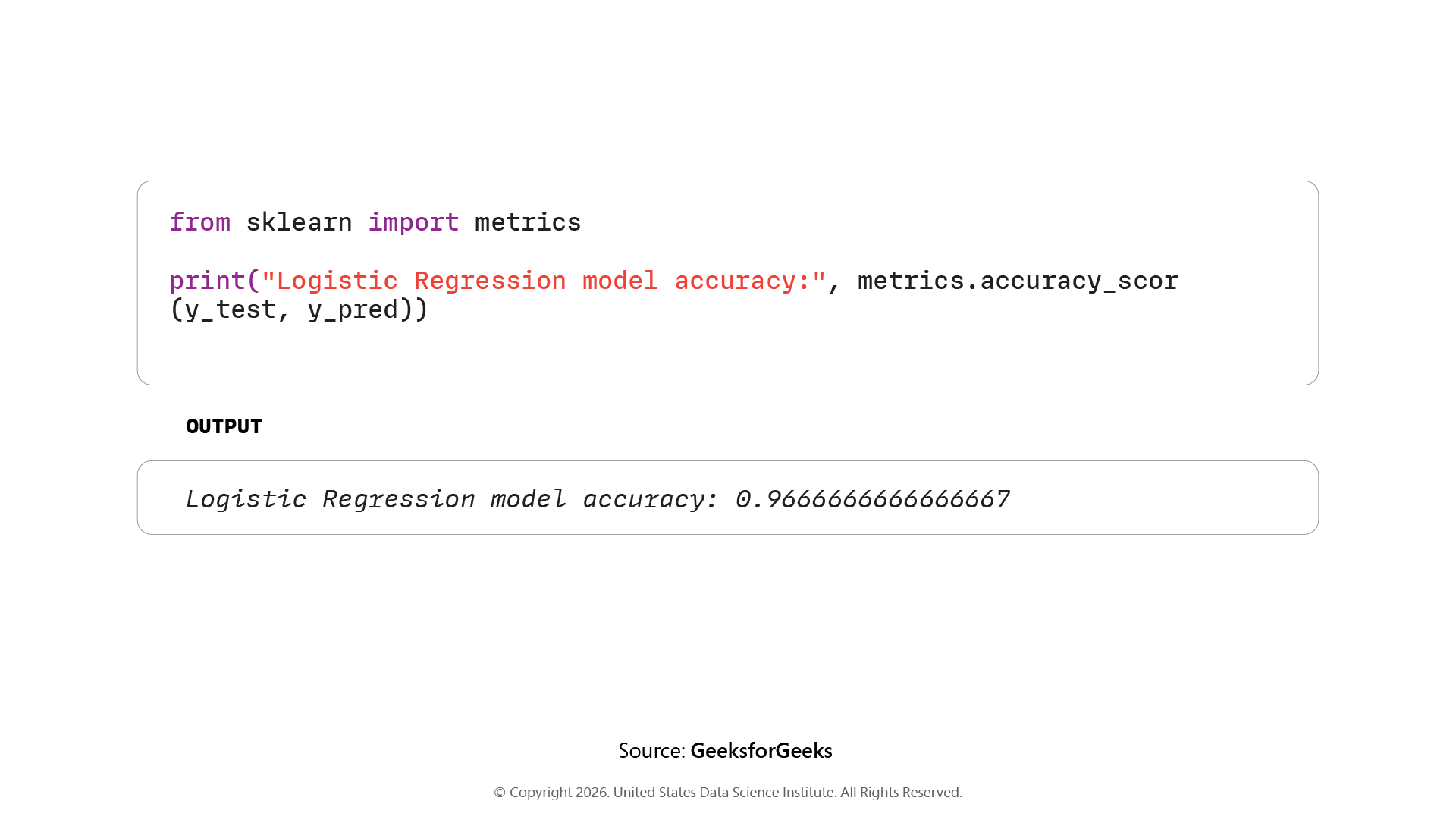
Step 6: Evaluating model accuracy and testing on new sample data:
Use accuracy_score to measure performance, the Iris model returns approximately 0.967. Pass a new 2D sample array into .predict() and map results to readable labels via target_names.
Where Is Scikit-Learn Used in Real-World Machine Learning Applications?
Production ML is used by industries in which structured tabular data is used for making decisions, and scikit-learn is the engine.
Conclusion
Scikit-learn will continue to be one of the most vital tools for creating scalable, interpretable, and production-ready machine learning systems. With the growing focus on classical ML, automation, and AI-based decision-making in enterprises, developers need to take their visualization skills to the next level, too.
Furthermore, professionals looking to upskill in machine learning, Python, data visualization, and AI-driven analytics can explore USDSI’s Data Science certification programs, designed to build practical, industry-relevant skills aligned with modern enterprise and AI workflows.
FAQs
No, it focuses on classical ML and uses TensorFlow or PyTorch for deep learning.
Yes, it processes large datasets with the help of Dask-ML or RAPIDS cuML.
Yes, the models can be simulated using joblib, FastAPI, AWS SageMaker, Vertex AI, or Azure ML.
This website uses cookies to enhance website functionalities and improve your online experience. By clicking Accept or continue browsing this website, you agree to our use of cookies as outlined in our privacy policy.