
Today, the amount of data an organization handle is more than ever. With the exponential increase in volume, velocity, and variety of data, the traditional centralized architectures often seem inefficient at scaling as per requirement, posing a huge challenge in effective data management.
So, to address this challenge, the two modern data management approaches, Data Mesh and Data Fabric, are widely used by organizations looking to gain a competitive edge in the data-driven business environment.
Both of these are designed to improve data accessibility, agility, and scalability; however, they differ significantly in their design philosophies, how they can be implemented, and their use cases.
Let's dive deeper and understand which approach is best for your organization.
WHAT IS DATA FABRIC?
Data fabric is a design concept that offers a unified architecture and a few sets of data services used to manage data across all environments, be it on-premises, over the cloud, hybrid, or edge.
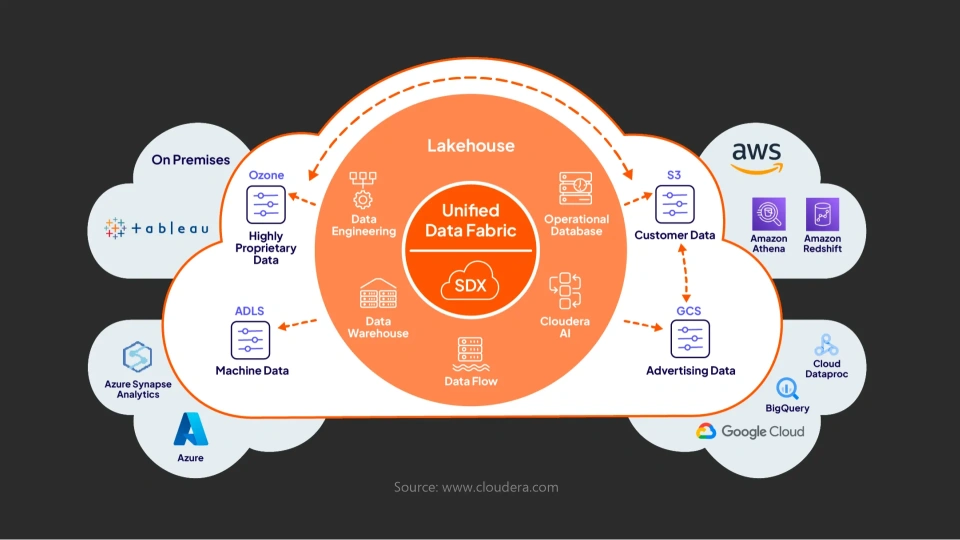
It uses metadata-driven and AI-powered automation to deliver consistent data management, data governance, and integration.
Here are some of the key features of Data Fabric:
It offers a single, logical view of data across distributed environments
Uses artificial intelligence and machine learning to automate data discovery, organization, integration, and governance.
It leverages active metadata to inform decisions about data movement, access, and security.
Can also work across multiple data sources and platforms, including different clouds, databases, and applications.
BENEFITS OF DATA FABRIC
Using data fabric for an organization’s data management offers great benefits, like:
DATA FABRIC TOP USE CASES
Data fabric is mostly used in the following scenarios:
WHAT IS DATA MESH?
A data mesh is a decentralized and domain-oriented data architecture approach. The data mesh considers data as a product and promotes data ownership and accountability at the domain level, for example, marketing, finance, or HR, instead of relying on a centralized data team.
Here are the important principles of data mesh:
This means data is owned and managed by the teams who generate and use it.
Here, each and every domain each responsible for delivering high-quality, well-documented, and accessible data products.
It consists of a platform that provides the tools and infrastructure needed to publish and consume data efficiently
The governance policies are established at an organizational level; they are implemented by individual domains.
NOTABLE BENEFITS OF DATA MESH
Here are some of the benefits organizations can consider while implementing data mesh.
DATA MESH TOP USE CASES
Data mesh can be used in the following places
DATA MESH VS. DATA FABRIC: KEY DIFFERENCES
|
Aspect |
Data Mesh |
Data Fabric |
|
Architecture Style |
Decentralized |
Centralized (logical view) |
|
Ownership Model |
Domain-driven |
IT/central data team-led |
|
Governance |
Federated |
Centralized |
|
Focus |
Organizational structure and culture |
Technology and infrastructure |
|
Data Management |
Distributed teams manage their own data |
Unified platform manages all data |
|
Automation |
Limited (dependent on domains) |
High (metadata- and AI-driven) |
|
Ease of Implementation |
Culturally challenging, requires maturity |
Technically complex, but can be vendor-supported |
CAN THEY EXIST TOGETHER?
Yes, both Data Mesh and Data Fabric are not mutually exclusive. In fact, many organizations are trying to explore ways to integrate them in a hybrid model that combines both of them:
In this hybrid model, data fabric provides the infrastructure while data mesh brings the organizational strategy for managing data effectively.
CHALLENGES TO IMPLEMENTATION
|
DATA FABRIC |
DATA MESH |
|
High cost and complex integration process |
Requires a significant cultural and operational transformation |
|
Dependency on mature metadata and automation capabilities |
Needs high technical maturity across domains |
|
Risk of vendor lock-in with propriety platforms |
There is a risk of inconsistent data quality without strong governance |
THE FINAL THOUGHTS
As data is becoming a strategic asset for organizations, they need a flexible, agile, and robust architecture to manage it. While data fabric offers a tech-centric solution, emphasizing centralized control and automation, which is ideal for environments that require consistency and speed, data mesh is a people-centric approach that promotes decentralization and domain ownership, which is mostly suitable for agile and collaborative organizations.
Data science professionals who want to master both data management architectures need to learn about their working and implementation. Enroll in top data science certifications from USDSI® to learn more about them and understand how your organization can leverage these architectures.
So, choosing between data mesh and data fabric, or a combination of both, typically depends on an organization’s size, data maturity, culture, and business goals. No matter which approaches you consider, the ultimate goal remains the same that is to turn data into a reliable, accessible, and valuable resource for the entire enterprise.
This website uses cookies to enhance website functionalities and improve your online experience. By clicking Accept or continue browsing this website, you agree to our use of cookies as outlined in our privacy policy.