
Data science workflows are often constrained not at the modeling stage, but much earlier in the process. Although AI is extensively applied in the areas of code generation, debugging, and summarization, these features only cover a minor portion of the workflow. A large part of the time is devoted to upstream activities.
As IBM highlights, finding, cleaning, and preparing the proper data for analysis can take up to 80% of a data scientist’s day. This stage is where delays accumulate, and efficiency is most impacted. AI is now expanding beyond isolated coding tasks to support data access, pipeline development, validation, and analysis.
In this blog, we will discuss the role of AI in the entire workflow of data science and where it can provide tangible contributions.
Code Generation to End-to-End Data Science Workflow Orchestration
AI has moved from sitting inside your editor to orchestrating work across your entire stack. Using Model Context Protocol (MCP), applications such as Claude Code and Codex can now access your cloud storage, databases, and version control. It is running multi-step workflows and not just generating snippets.
Complete Data Science Workflow Beyond Model Development
All the attention is directed towards model building. But any working data scientist knows that it is just a fraction of the time spent on a project.
The actual workflow is more convoluted and lengthy, and AI is now capable of handling all of those parts.
Where Traditional Data Science Workflows Start to Break Down
Traditional processes do not randomly stop working; they always stop working at the same pressure points.
These failures are not new, and this point is exactly where AI connects the right tools, which will help to hold the workflow together.
The image illustrates that traditional ETL pipelines involve multiple handoffs and transformation stages, increasing the risk of delays, failures, and data inconsistencies.
Why is Data Quality and Visibility Central to Debugging and Iteration
AI productivity frequently ignores a crucial element: data is essential for model debugging. When outputs appear incorrect, the problem is typically upstream in the data rather than the model.
Pipeline visibility is so crucial. Errors can be more difficult to identify when they are concealed by clean-looking outputs. Validating transformation logic and tracing anomalies early is critical, as pipeline-level checks prevent issues from compounding later.
How AI Integrates Across Data Science Workflow Stages
Multiple stages of the data science workflow are supported by AI; however, the degree of support varies. AI has advantages over all stages for execution purposes, but offers less support for making domain-specific decisions.
During data pipelining, AI can not only generate ingestion scripts, map schemas, load and troubleshoot data, but it can also perform all of these tasks. In the analysis stage, it can execute queries, detect trends, and summarize results, as long as the inquiry is sufficiently clear.
However, there will always be a need for domain knowledge and analytical reasoning when trying to identify causation from patterns recognized by the algorithms generated by AI.
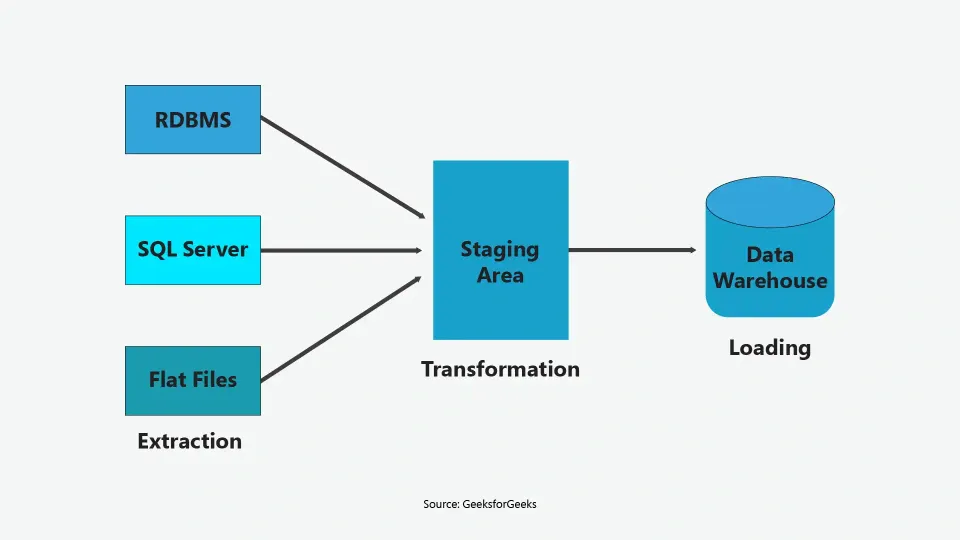
The data pipeline diagram illustrates how AI integrates across stages, from extraction to transformation and loading, within a structured data science workflow.
Role of the Modern Data Scientist
The role of a data scientist is shifting from manual execution to judgment-driven work. As AI handles more tasks, the focus moves toward decision-making, validation, and context.
Conclusion
As AI evolves within Data Science, the experience has significantly shifted from a coding-based generation to a full end-to-end execution. AI is now part of managing pipelines or integration and performing faster analyses. The next phase demands visibility and not just speed.
Traceable logic, clean data flows, and proactive monitoring are key characteristics of reliable systems. Data scientists who succeed will guide AI, not just use it, combining automation with informed judgment.
FAQs
1. How does AI improve collaboration in data teams?
AI streamlines handoffs, standardizes workflows, and improves visibility, enabling data scientists and engineers to work simultaneously instead of sequentially.
2. Can AI fully manage real-time data workflows?
AI supports real-time processing and monitoring, but system reliability and performance still require human oversight.
3. What risks come with relying too much on AI?
Over-reliance can lead to hidden errors, flawed assumptions, and reduced accountability without proper validation.
This website uses cookies to enhance website functionalities and improve your online experience. By clicking Accept or continue browsing this website, you agree to our use of cookies as outlined in our privacy policy.