
Organizations are constantly generating and collecting information from various sources in today's data-driven world. This data holds immense potential for uncovering valuable insights, but only if it can be efficiently managed and analyzed. Here's where data ingestion pipelines come into play. These pipelines are the backbone for integrating data from disparate sources, transforming it into a usable format, and delivering it to analytics and data science platforms for further processing.

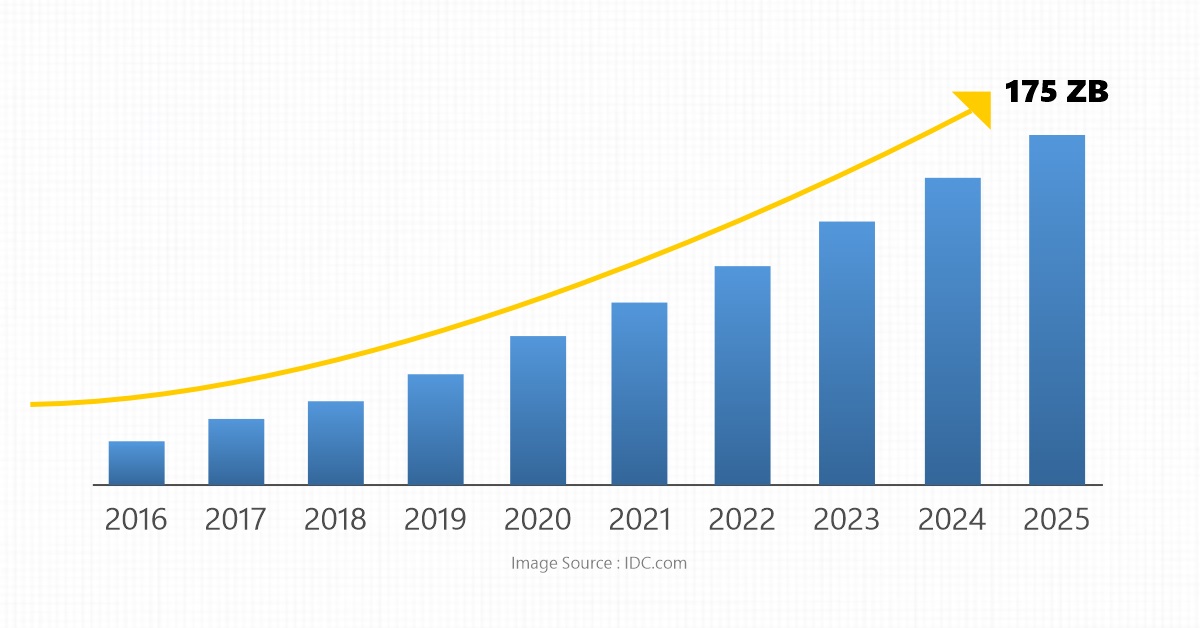
The representation above showcases a massive surge in global data generation volume over the years through 2025 (IDC.com). This massive explosion of data sets demands a core understanding of smarter ways of data ingestion. This paper explores the core building blocks of a data ingestion pipeline and how they contribute to efficient data management and leverage an enhanced data science platform.
Understanding Data Ingestion Pipelines:
A data ingestion pipeline is an automated workflow that extracts data from various sources, transforms it as needed, and loads it into a target destination like a data warehouse, data lake, or other analytics platform.
3 Key Stages in Data Ingestion:
Building Blocks for Efficient Data Pipelines
Effective data ingestion pipelines rely on several crucial building blocks to ensure smooth operation and efficient data management:
3 Robust Data Ingestion Techniques
This involves collecting and processing data in large, discrete chunks at regular, scheduled intervals.
It is the constant flow of data, processed nearly in real time; bringing forth massive insights for decision-making.
CDC captures and tracks changes in data sources to take immediate action. It efficiently processes updates and often complements batch and real-time processing.
How to build an end-to-end data pipeline from scratch?
Define Problem>> Requisites>> Build Pipelines>> Monitor
Begin by understanding the business goals that can be served by making various pipelines. It must be followed by preparing a checklist on the type, size, frequency, and data source. Thereafter, synchronizing the pipeline’s output for desirous applications. eventually, the processes culminate with monitoring the pipeline, offering feedback, and eliminating potential issues.
5 Popular Data Ingestion Pipeline Tools:
Apache Kafka is a distributed event store and stream-processing platform. It is an open-source system developed by the Apache Software Foundation that aims to offer a unified high-throughput, low-latency platform for handling real-time data feeds.
Data warehouse, aka Enterprise data warehouse; is a system used for reporting and data analysis and is considered a core component of business intelligence. These are central repositories of integrated data from one or more disparate sources.
Hevo is a fully-automated unified data platform, ETL platform; that allows you to load data from over 150 sources into your warehouse, transform, and integrate the data into any target database.
Airbyte is the next open-source data portability platform that runs from your infrastructure directly. It is an open-source data ingestion tool with a free version for small businesses to target data extraction and data loading.
Confluent Cloud is a cloud-native service for Apache Kafka used to connect and process data in real time with a fully-managed data streaming platform. It is widely known for its scalability.
Benefits of Efficient Data Ingestion Pipelines
By incorporating these building blocks, organizations can achieve several benefits from well-designed data ingestion pipelines:
Comprehending Data ingestion pipelines is the foundation for unlocking the true potential of data. facilitating data-driven decision-making is of utmost importance with a targeted data ingestion pipeline; designed with core data management strategies. Explore the basics of advanced data management components and tools to guide an enhanced data science mark ahead.
This website uses cookies to enhance website functionalities and improve your online experience. By clicking Accept or continue browsing this website, you agree to our use of cookies as outlined in our privacy policy.