
SQL drives decisions, pipelines, and products; however, when a query fails, clarity is lost. In distributed systems such as Apache Spark, the process of debugging is guesswork. The execution plans change, intermediate data remain obscure, and problem isolation takes longer than necessary.
According to an IBM Institute for Business Value study, 43% of COOs rank data quality as their top priority, and over a quarter of organizations lose more than $5 million annually due to poor data quality. What should be a quick fix often turns into a slow, resource-heavy process.
This blog discusses the role of DeSQL in making the SQL debugging process in complex data environments simpler. You will know the fundamental issues that cause the issue of debugging at scale and how a more organized method can reduce errors and save time and money.
Introducing DeSQL: Interactive SQL Debugging Made Simple
DeSQL is an interactive step-through debugger that is designed to debug SQL statements that run on distributed computing systems (DISC). Its major target platform is Apache Spark. It exposes the known breakpoint debugging experience to SQL, based on DISC, without requiring manual query decomposition or job re-execution.
Three Fundamental Stages of DeSQL:
Stage 1: Automated Query Decomposition
DeSQL reads the SQL query with grammar production rules to produce a set of all possible subqueries. Each will represent a single logical step in executing the query.
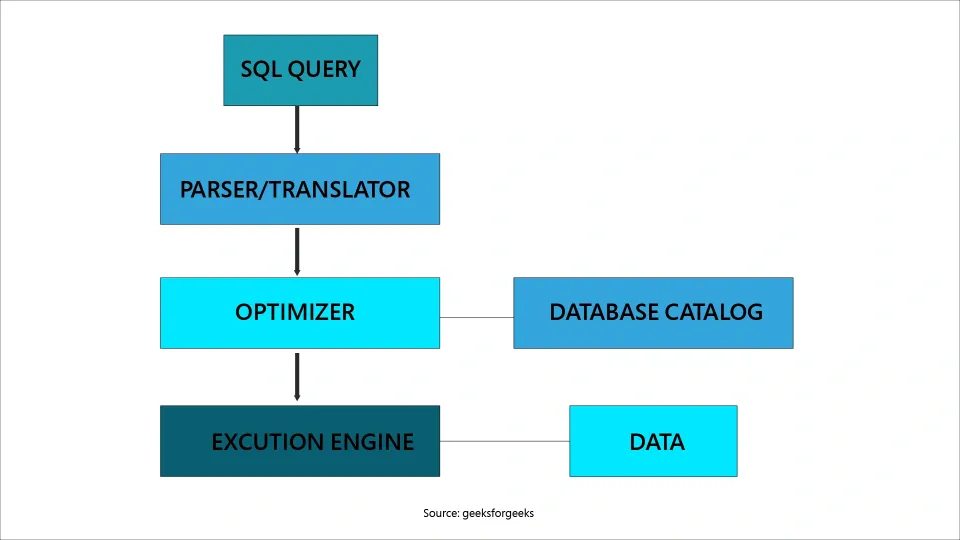
Stage 2: Taint Analysis
In query optimization and physical plan generation, DeSQL uses a fine-grained taint analysis to trace all the physical execution tasks to their corresponding subqueries.
Stage 3: Data Regeneration
For queries where intermediate data is optimized, DeSQL reconstructs it by tracing back to the nearest valid materialization stage.

The adoption of DeSQL is easy, and only two lines of code are needed to integrate it. Once it is enabled, it will give the developers a hierarchical list of all the constituent subqueries, and they can get the resultant intermediate data.
How DeSQL Breaks Down Complex Queries
The core of the DeSQL lies in its query decomposition engine, which is automated and takes off the load of query decomposition. Instead of using the intuition of developers, DeSQL uses the rules of SQL grammar to determine the natural decomposition points in any given query.
The important points of this process are:
Optional elements of a grammar rule, like a WHERE clause, are processed by DeSQL to produce two subqueries, one with the optional element included and the other without.
Production rules have alternate sequences, which DeSQL produces as separate subqueries, in a logical expansion of each alternate selection.
Each logical plan node is labeled with a distinct identifier known as OpIndex and is propagated throughout all the plan steps. This will include parsing, optimization, and code generation, making sure that the correct mapping between subqueries and physical operations is done.
Debug data is generated only when requested, minimizing unnecessary computation and overhead.
With these mechanisms in place, developers can now see how complex queries execute in practice, step by step, without guesswork.
DeSQL in Action: What Developers Actually See
Building on DeSQL's query decomposition engine automates subquery breakdown through optional clause handling, alternate sequence expansion, taint propagation, and lazy materialization.
Here is a side-by-side look at how these mechanisms translate into a real debugging experience, transforming manual guesswork into structured, step-through clarity in Apache Spark environments.
|
Aspect |
Without DeSQL |
With DeSQL |
|
When a query fails |
Guesswork through raw logs and execution plans |
Navigable subquery tree showing every logical step |
|
Debugging workflow |
Manually insert intermediate CREATE TABLE AS SELECT statements and re-run partial jobs |
Step through each decomposed subquery node and inspect output on demand |
|
Finding a low row count issue |
Repeated manual interventions across JOIN, WHERE, and GROUP BY separately |
Step through subquery sequence and pinpoint the exact clause dropping rows, often in one session |
|
Team collaboration |
Senior engineer decodes execution plan for junior teammate |
Both navigate the subquery tree together; transparent and transferable across experience levels |
|
Optimizer rewrites |
Developers lose track of which physical task maps to which logical step |
OpIndex propagation keeps every physical task anchored to its originating subquery |
|
Time to resolve |
Multiple job re-executions and hours of log analysis |
Resolved within a single interactive debugging session |
|
Business impact |
Extended pipeline downtime, higher data quality risk, and millions in annual losses |
Reduced downtime, faster fixes, measurable drop in debugging overhead |
|
Integration effort |
Custom tooling or manual query decomposition required |
Two lines of code to enable a hierarchical subquery list generated automatically |
Boosting Productivity and Reducing Costs with DeSQL
DeSQL minimizes the use of intuition, trial-and-error, and guesswork by automating query decomposition, as well as supporting step-through debugging to assist in query creation. Less time is wasted in job re-execution by the developers, pipelines also take less downtime, and teams can work together in debugging more complicated queries.
In the case of enterprises, this is translated to:
Where is SQL Debugging Headed in Modern Data Processing?
DeSQL also opens up the new frontier of SQL debugging, and it bridges the gap that had kept developers skeptical about using SQL in DISC systems. Its framework, query decomposition, taint-based tracing, and lazy data materialization, are not limited to Apache Spark. It can also be extended to other distributed SQL engines, such as Apache Hive, with a specific engineering effort.
Looking forward, SQL debugging may evolve to include:
This ensures that large-scale SQL development becomes faster, safer, and more transparent.
Conclusion
DeSQL is setting a new age of SQL development on a massive scale. It allows teams to work more quickly, collaborate, and be confident in their work by simplifying query decomposition, tracing errors, and creating any intermediate data again.
With the ever-increasing volume of data and distributed systems becoming the key for enterprises, it will be necessary to adopt such a tool as DeSQL to create reliable, efficient, and future-oriented data pipelines.
FAQs
1. Does DeSQL require deep knowledge of Apache Spark internals?
No, DeSQL abstracts most of the complexity. Developers can debug queries step-by-step without needing to understand Spark’s internal execution plans in detail.
2. Can DeSQL be used for learning SQL debugging as a beginner?
Yes, its structured breakdown of queries makes it useful for beginners to understand how queries execute and where errors occur.
3. How does a data science certificate help?
Data science certifications build strong data handling skills that further help to debug queries in tools like DeSQL.
This website uses cookies to enhance website functionalities and improve your online experience. By clicking Accept or continue browsing this website, you agree to our use of cookies as outlined in our privacy policy.