
Training data is the foundation on which every AI system is built. The sophistication of a model's architecture, the scale of its compute resources, and the expertise of the team behind it all matter, but none of it produces reliable outcomes if the underlying data is inadequate.
The global AI training dataset market is projected to reach $16.32 billion by 2033 growing at a CAGR of 22.6% (Grand View Research), that reflects the degree to which training data has become a strategic priority across the enterprise AI landscape.
This read highlights what AI training data is, its diverse forms, and why data quality consistently outweighs volume as a determinant of model performance.
What is AI Training Data?
AI training data is the curated set of examples a model processes during development to learn how to perform a specific task. Rather than operating on pre-programmed rules, machine learning models identify statistical patterns across large volumes of labeled or structured inputs, building internal representations that generalize to new data at inference time.
The composition of that dataset directly shapes model behavior. Incomplete, inconsistent, or unrepresentative training data produces models that reflect those deficiencies in production, regardless of architectural sophistication. In applied AI, training data is not a preliminary step. It is the primary variable determining whether a system performs reliably at scale.
Understanding AI’s Information Sources
The sources vary depending on the task. Listed below are the primary channels through which training data is collected.
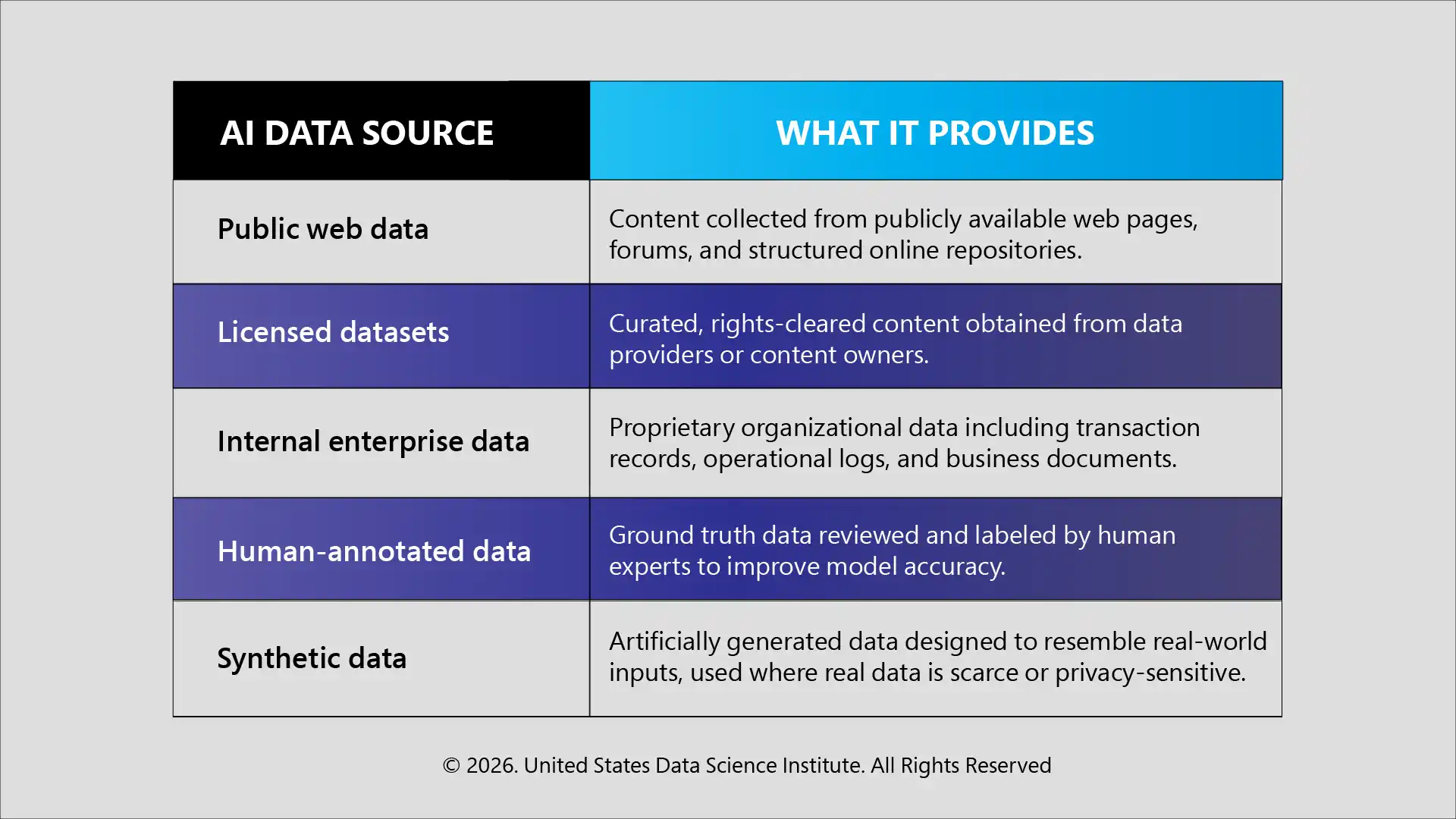
Most AI systems combine multiple sources. A large language model might use web-scraped text, licensed book content, and human feedback together.
Types of AI Training Data
The type of data a model needs depends entirely on the task it is being trained to perform. Listed below are the primary data types used across modern AI systems.
Used for language models, chatbots, and translation systems. The sources are books, articles, websites, and academic papers.
It can be used in computer vision applications to identify objects, recognize faces, or even to drive self-driving cars. It needs careful labeling of the content within each frame.
Recommended for applications such as voice assistants and speech recognition devices. It contains recorded speech, environmental sounds, and music.
Finance, healthcare, operations, and structured numeric data for predictive modelling.
Uses more than one type of data at the same time, like a pair of text and image data for models that take both into account.
Read USDSI® insights on A Detailed Take on Generative AI in Data Science Workflow. A closer look at how generative AI is being applied across real data science workflows, from data preparation to model development and deployment.
Considerations for High-Quality Training Data
Volume alone does not produce a reliable model. High-quality training data consistently shares these aspects:
Challenges in AI Training Data
Building and maintaining high-quality training datasets is one of the toughest problems in applied AI. Listed below are the challenges that consistently surface across organizations working with AI training data.
Data Scarcity in Specialized Domains
In radiology, legal analysis, or rare language processing, labeled data volumes are too small to train reliable models without significant human annotation effort.
Bias in Training Data
If the data used in models is based on historical inequalities or non-representative sources, the models will contain those biases and will yield unequal and/or inaccurate results for under-represented populations.
Privacy and Regulatory Constraints
GDPR, CCPA, HIPAA and AI-specific regulations apply to data involving individuals. Lack of consent and governance means a lot of legal exposure when using personal data.
Data Exhaustion
The stock of publicly available high-quality text data is finite, and frontier models are consuming it at an accelerating rate. Synthetic data, artificially generated content designed to mimic real-world patterns, is emerging as the primary industry response to this growing constraint.
Message for Data Science Professionals
The conversation around AI is shifting from models and algorithms toward the data underneath them. Training data quality, provenance, governance, and ethical sourcing are increasingly where the real work of building reliable AI happens.
For data science professionals, this shift creates a clear opportunity. Understanding how training data is sourced, structured, labeled, and governed is becoming one of the most in-demand capabilities in the field. USDSI® data science certifications help build applied expertise, equipping professionals to work effectively at the intersection of data, AI, and organizational needs.
Explore USDSI® Data Science Certifications.
FAQs
What is the difference between training data and test data?
Training data is what a model learns from. Test data is a separate set used afterward to evaluate performance on examples the model has never seen.
Can AI systems be trained on synthetic data?
Yes. Synthetic data is increasingly used where real data is scarce, sensitive, or expensive to collect.
What is data annotation and who does it?
Data annotation is the process of labeling raw data so AI models can learn from it, carried out by human reviewers through specialized annotation platforms and services.
This website uses cookies to enhance website functionalities and improve your online experience. By clicking Accept or continue browsing this website, you agree to our use of cookies as outlined in our privacy policy.