
When machine learning models fail in production, teams assume that it is a problem with the model and the algorithm. They change architectures, tweak parameters, or experiment with another architecture, hoping that this will increase performance.
The issue is typically the information.
Many industries indicate that data quality is a primary reason for the failure of many ML projects. Gartner’s 2026 research reveals that only 28% of AI use cases in infrastructure and operations achieve expected ROI, while a significant portion either fails or stalls before reaching production impact.
This illustrates the obvious fact that the better the data the models are trained on, the better the results will be. Incomplete, inconsistent, or biased data will result in a flawed model that will lead to inaccurate predictions.
Why Data Quality Matters More Than Algorithms
A machine learning model does not understand the world. It learns statistical patterns from whatever data it is given. If that data is noisy, incomplete, or skewed, the model absorbs those flaws and treats them as truth.
Clean data tends to produce stable, reliable performance. Messy data tends to produce models that look fine in testing but behave unpredictably once deployed. This is part of why data quality is increasingly treated as the foundation of ML work, not an afterthought handled by a separate team before the “real” modeling begins.
Hidden Ways Poor Data Breaks ML Models
Most data problems are subtle and often appear during collection, integration, or preprocessing, only becoming visible once a model is in production. Listed below are key factors:
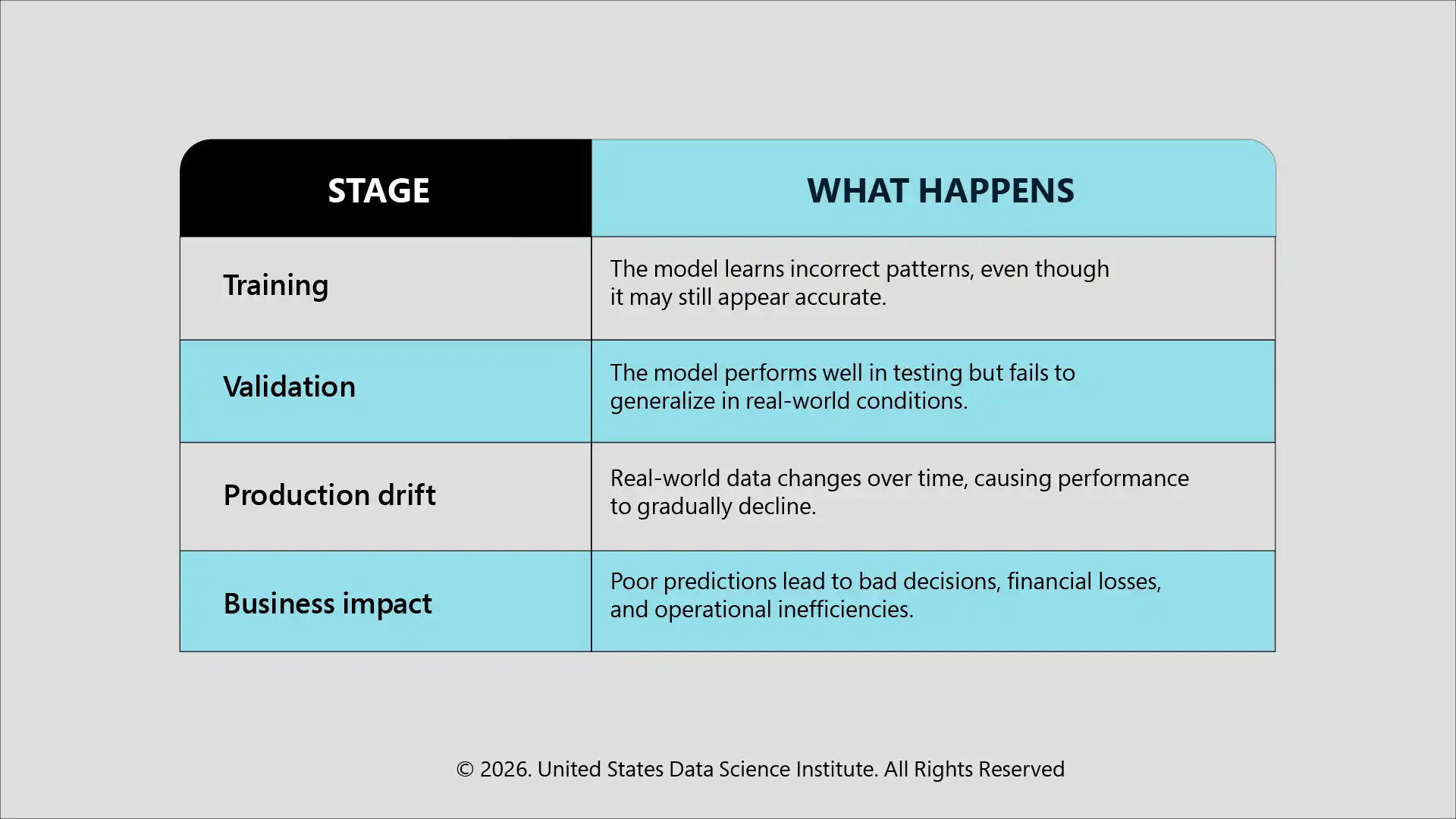
How Poor Data Quality Leads To ML Failure
When poor-quality data enters a workflow, its problems do not stay contained. They move downstream into every system that depends on the model’s output, often without any visible warning that something has gone wrong.
These issues tend to surface at different points across the lifecycle of a model.
Real-World Example
Picture a retail recommendation engine trained on historical purchase data that has missing timestamps, duplicate transactions, and incomplete product categories. In practice, this model might surface irrelevant recommendations, miss obvious seasonal trends, and underperform exactly when it matters most, such as during a major sales event.
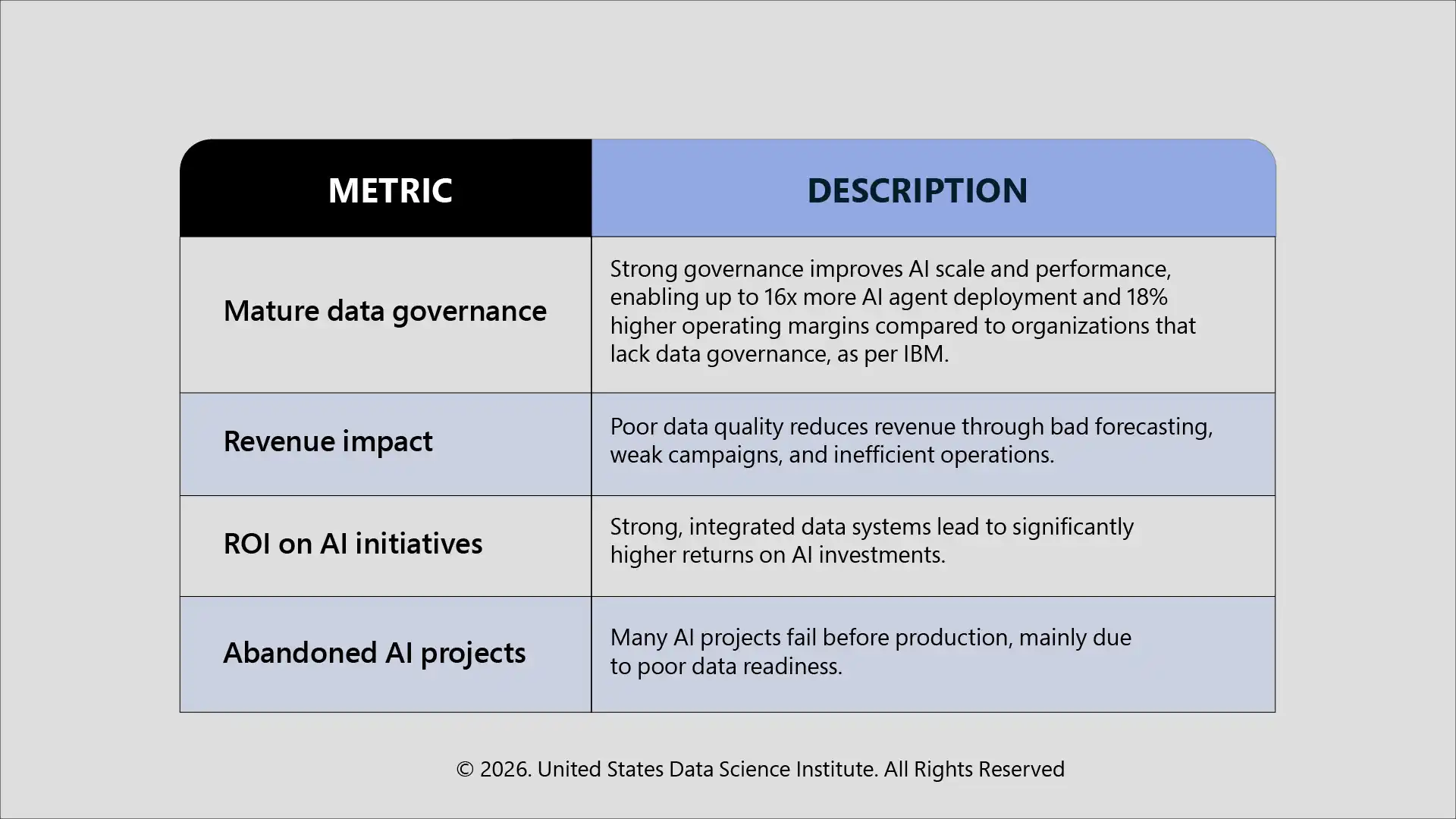
Cost Of Getting This Wrong
Poor data quality has direct financial and operational consequences that grow as AI systems scale across an organization, as listed below:
Key Dimensions Of Data Quality
A dependable ML system rests on data that holds up across six dimensions:
How To Improve Data Quality In Machine Learning
Improving data quality is not a one-time cleanup project. It is an ongoing practice that includes:
From Clean Data To Clear Insight
Data quality shapes more than model performance. It shapes whether the insights pulled from that model can be trusted and explained to others. As the USDSI® insight What Powers Data Storytelling in 2026 explores, the strength of any data narrative depends entirely on the integrity of what sits underneath it. A chart or dashboard built on flawed data does not just mislead in the moment. It quietly undermines confidence in everything that team produces afterwards.
Building the Competency For Successful ML Deployments
Spotting and fixing data quality issues before they reach a model is one of the more underrated skills in data science. It is also what separates professionals who can build a model from those organizations that actually trust to put one into production. For those looking to build that competency formally, USDSI® data science certifications cover data pipeline design, governance practices, and the analytical foundations needed to make sure a model's data can actually support it. Start your learning journey today.
FAQs.
Can a sophisticated ML model compensate for poor quality training data?
No, a model trained on flawed, biased, or incomplete data will produce unreliable outputs regardless of architectural sophistication.
What skills are most valuable for professionals working on data quality for ML systems?
Data validation, pipeline design, statistical profiling, data governance, and familiarity with data observability tools are the most valuable skills for this work.
What job roles focus specifically on data quality within data science teams?
Data Quality Analyst, Data Governance Specialist, ML Data Engineer, and Data Observability Engineer are roles dedicated to maintaining data integrity across ML pipelines.
This website uses cookies to enhance website functionalities and improve your online experience. By clicking Accept or continue browsing this website, you agree to our use of cookies as outlined in our privacy policy.